













Be it hiring or employee engagement or validating promotions, choosing the right assessments is a pivotal decision that can make or break the success of a business. Two critical properties of an assessment, from a psychometric/statistical standpoint, are reliability and validity.
What is Reliability and Validity?
Reliability and validity are concepts used to evaluate the quality of assessments. They indicate how well a method, technique or test measure a behavioural attribute or an ability.
Reliability is the consistency of a measure. Look at it this way, you recently tasted an ice cream and you loved it. You started having it once every week. However, the ice cream does not taste the same every time.
Similarly, a test taken multiple time with time gap in between should more or less produce similar results. This consistency in results is called Reliability, that is, how well one can rely on the test results.
Validity is the accuracy of a measure. As watered down as this may sound, validity is when you order a chocolate ice cream and get a chocolate ice cream not a vanilla.
Validity of a test refers to how well the test is measures what it intends to measure.
For example, Freight Transport, our freight delivery based real-life simulation of risk-taking and impulsive decision making, is developed based on a Psychology experiment called Balloon-Analogue-Risk task (BART) and also with the understanding of Decision making through experience (experimental paradigm).
Organizations generally look for a pre-employment test that can be used for a long period of time without any deviations in the results.
Measuring only reliability or validity isn’t enough; reliability ensures consistent results, but without validity, those results may not truly measure what they’re intended to. For assessments to be effective, both reliability and validity must work together to provide accurate, meaningful insights.

Types of Reliability
Psychologists consider three types of consistency: over time (test-retest reliability), across items (internal consistency), and across different researchers (inter-rater reliability).
1. Test-Retest reliability
When researchers measure an attribute that they assume to be consistent across time, then the scores they obtain should also be consistent across time. Test-retest reliability is the extent to which this is actually the case.
For example, intelligence is generally thought to be consistent across time. A person who is highly intelligent today will be highly intelligent next week. This means that any good measure of intelligence should produce roughly the same scores for this individual next week as it does today.
2. Internal Consistency
A second kind of reliability is internal consistency, which is the consistency of people’s responses across the items on a multiple-statements test. In general, all the items on such test are supposed to reflect the same underlying attribute being measured. In that case, people’s scores on those items should be correlated with each other.
For instance, to evaluate the level of satisfaction of your customers via your customer services, you should measure overall satisfaction. Options should be on Likert scaling, varying from Strongly Agree to Strongly Disagree.
3. Inter-rater Reliability
Many behavioural measures involve significant judgment on the part of an observer or a ‘rater’. Inter-rater reliability is the extent to which different observers are consistent in their judgments. It indicates how consistent test scores are likely to be if the test is scored by two or more raters.
Types of Validity
1. Face validity
Face validity, also called logical validity, is a simple form of validity where you apply a superficial and subjective assessment of whether or not your test measures what it is supposed to measure. You can think of it as being similar to “face value”, where you just skim the surface in order to form an opinion. It is the easiest form of validity to apply to research.
For example, Lila is a researcher who has just developed a new assessment that is meant to measure mathematical ability in college students. She selects a sample of 300 college students from three local universities and has them take the test. After the students complete the test, Lila asks all 300 participants to complete a follow-up questionnaire.
In the questionnaire, Lila asks the participants what they think the purpose of the test is, what ability they believe is being measured, and whether or not they feel the assessment was an adequate measure of their mathematical ability. After analysing the follow-up results, Lila finds that most of the participants agree that Lila’s assessment accurately measures their mathematical ability. Lila has just demonstrated that her assessment has face validity.
2. Predictive Validity
Assessing predictive validity involves establishing that the scores from a measurement procedure (e.g., a test or survey) make accurate predictions about the attribute they represent (e.g., constructs like intelligence, achievement, burnout, depression, etc.). Such predictions must be made in accordance with theory; that is, theories should tell us how scores from a measurement procedure predict the behaviour/ability in question.
In order to be able to test for predictive validity, the new measurement procedure must be taken after the well-established measurement procedure. By after, we typically would expect there to be quite some time between the two measurements (i.e., weeks, if not months or years).
3. Construct Validity
A common method used to satisfy construct validity is to use an already established and reliable measure of that same construct.
For instance, you wish to develop a new measure to assess intelligence. Construct validity is found by ensuring the new measure precisely predicts the findings derived from the theory of intelligence.
4. Convergent Validity
Convergent Validity is a sub-type of construct validity. Construct validity means that a test designed to measure a particular construct (i.e., intelligence) is actually measuring that construct. Convergent validity takes two measures that are supposed to be measuring the same construct and shows that they are related.
Let’s say you were researching depression in college students. In order to measure depression (the construct), you use two measurements: a survey and participant observation. If the scores from your two measurements are close enough (i.e. they converge), this demonstrates that they are measuring the same construct. If they don’t converge, this could indicate they are measuring different constructs (for example, anger and depression or self-worth and depression).
5. Content Validity
It refers to the actual content within a test. A test that is valid in content should adequately examine all aspects that define the objective.
Content validity is not a statistical measurement, but rather a qualitative one. For example, a standardized assessment in 9th-grade biology is content-valid if it covers all topics taught in a standard 9th-grade biology course
6. Criterion Validity
Criterion validity measures how well one measure predicts an outcome for another measure. A test has this type of validity if it is useful for predicting performance or behaviour in another situation (past, present, or future).
Let’s look at an example –
I. A job applicant takes a performance test during the interview process. If this test accurately predicts how well the employee will perform on the job, the test is said to have criterion validity.
II. A graduate student takes the GRE. The GRE has been shown as an effective tool (i.e., it has criterion validity) for predicting how well a student will perform in graduate studies.
The first measure (in the above examples, the job performance test and the GRE) is sometimes called the predictor variable or the estimator. The second measure is called the criterion variable as long as the measure is known to be a valid tool for predicting outcomes.
7. Divergent Validity
Divergent validity helps to establish construct validity by demonstrating that the construct you are interested in (e.g., anger) is different from other constructs that might be present in your study (e.g., depression). To assess construct validity in your dissertation, you should first establish convergent validity, before testing for divergent validity.
What is a ‘Good’ Reliability and Validity Score?
Knowing the ideal score of a reliable and validity of a pre-employment test is important because if you fail to match these standards then your results might not be accurate.
Good Validity Score
Validity coefficient number ranging between 0–1 indicates the relationship between the test and the measure of the criterion. The following table shows the required values for a valid test and how each value can be interpreted.
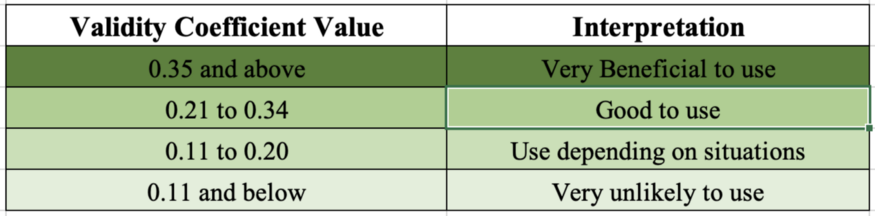
Good Reliability Score
For a good reliability score, one of the common measures of internal consistency is Cronbach Alpha value. The following table shows the required values and their interpretation.
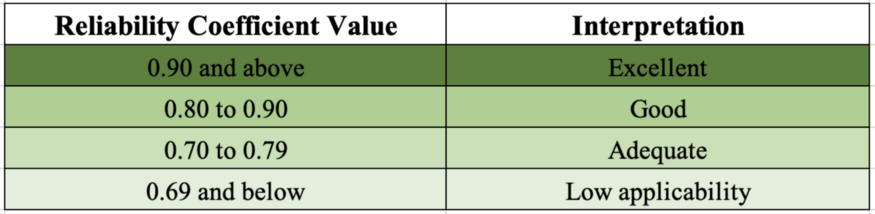
Make sure to consider these psychometric properties before you commit to an assessment for your organization.
The Future of Reliability and Validity Testing
Looking ahead, the future of reliability and validity in assessments is promising. Advancements in technology and data analytics will allow us to refine measurement accuracy, enhancing both the reliability and validity of our tools. As these methodologies evolve, assessments will become even more precise and predictive. This will help set new standards for quality and dependability in evaluating skills and potential.
PerspectAI’s assessments are rooted in science, and hold good reliability and validity. We have conducted multiple rounds of testing, and most of PerspectAI’s assessments consistently achieve reliability coefficients above 0.6, ensuring dependable results across various uses.
Our games are built on gold-standard Cognitive Psychology experiments developed by renowned institutions and research departments around the world. Adapting from peer-reviewed research-based experiments allows us to reap the benefits of powerful psychometrics while combining the benefits of data and technology. Book a demo with us today to standardize your hiring assessments – and also make it fun along the way!















